Fernando Conde es uno de los investigadores sociales españoles más importantes. Fiel seguidor de las escuelas de Alfonso Ortí, Ángel de Lucas y Jesús Ibáñez y creador de cursos universitarios sobre Sociología del Consumo, ha trabajado desde el instituto Cimop, que fundó y codirigió durante muchos años, para una gran parte de las marcas más punteras de nuestro mercado. Una de sus más importantes aportaciones fue siempre proporcionar un aspecto cualitativo a los datos cuantitativos, o viceversa: introducir aspectos matemáticos (geométricos, o topológicos), a estudios de base cualitativa.
Fernando es una de esas pocas personas con una formación mixta, lejos de la división entre ciencias y letras, y una cultura casi universal, con el que siempre da gusto conversar y, por supuesto, trabajar.

Hace ya casi cuarenta años que nos conocemos. En aquella época él trabajaba aún en Emopública y yo lo hacía en RTVE. Allí coincidimos, él como técnico de la empresa que hacía los estudios y yo como parte de la empresa cliente. Recuerdo especialmente su participación varios años en lo que denominábamos ICC (Investigación Cualitativa Continua), aunque seguro que también colaboró en algunos otros estudios.
Desde entonces Fernando es, seguramente, el técnico con el que he compartido más estudios a lo largo de mi carrera.
A principios de los noventa, cuando yo ya estaba en el lado publicitario del mercado, en Central Media, le pedí ayuda para buscar algún estudio diferencial, que nos ayudara a ofrecer productos e ideas diferentes a nuestros clientes. De ahí surgió Atlas, un estudio que mantuvimos a lo largo de más de veinte años. Atlas era una reelaboración del EGM (Estudio General de Medios) mediante diferentes análisis multivariantes, en especial el AFCM (Análisis Factorial de Correspondencias Múltiples), que nos permitía ver y analizar la evolución de la sociedad española, de sus equipamientos y consumos de medios y productos a lo largo de todos esos años en los que se realizó el estudio. En la última época del estudio, en años alternos, se analizaba el estudio AIMC Marcas.
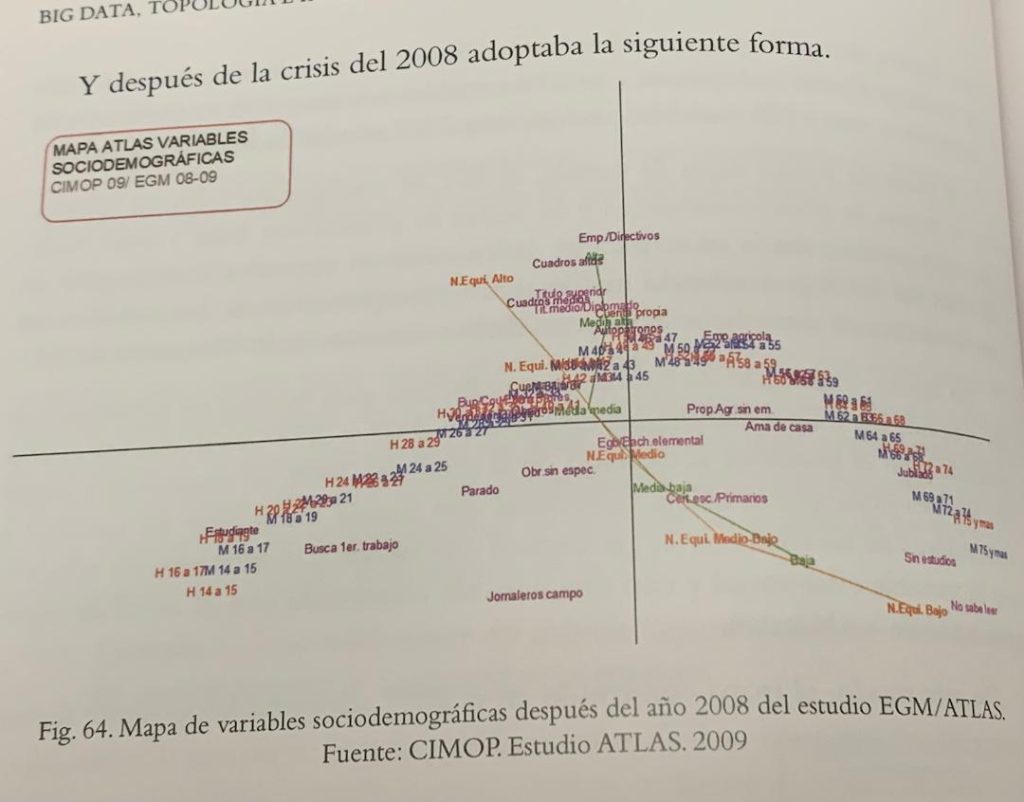
Atlas era ya un antecedente, si no del big data, sí del uso masivo de grandes cantidades de datos para buscar nuevas relaciones y representaciones de los mismos. De hecho es uno de los ejemplos que Fernando Conde incluye en su libro (entre las páginas 178 y 182) para ilustrar las conexiones entre los análisis estadísticos más tradicionales y los nuevos introducidos por las técnicas agrupadas como data science o data analytics.
El libro, Big data, topología e investigación social trata de introducir una buena dosis de racionalidad al mundo del big data y sus análisis.
Partiendo de una gran base teórica y de análisis, el autor profundiza en los efectos que la generación y uso masivo de datos está produciendo, hasta llegar a la digitalización de la vida misma.
La mayor parte de esos datos no se producen (ni en muchos casos se utilizan) con fines de investigación social, sino con objetivos comerciales. Además, casi la totalidad de esos datos son propiedad de un pequeño grupo de corporaciones, bien de Estados Unidos, bien de China.
Sin ocultar los problemas que esta nueva situación plantea al investigador social, Conde profundiza en las ventajas y las posibilidades que esta sobreabundancia de datos puede proporcionar a los investigadores.
El libro se estructura en trece capítulos agrupados en cuatro partes.
Los cuatro capítulos de la primera parte se centran en establecer el debate sobre big data en el campo de las ciencias sociales: desde la definición de Big data y el análisis de la generación de esos datos masivos hasta su caracterización, con las famosas cuatro uves: variedad, volumen, velocidad y visualización. Todo ello en el marco de un gran aparato teórico.
Los tres capítulos de la segunda parte abordan el tema de la caracterización de las huellas y los datos digitales: Del big data como una modalidad moderna y masiva del tradicional registro de datos y del proceso de transformación de las huellas en datos digitales, con el uso masivo de las correlaciones estadísticas, que se relacionan con las técnicas tradicionales, pero también con los no siempre inocentes ni neutrales algoritmos. Termina con una reflexión sobre sistemas de representación, mapas y gráficos.

Los cuatro capítulos de la tercera parte entran ya de lleno en el tema central del libro: la topología y sus aportaciones a las formas de visualización y representación de esas grandes masas de datos. Desde los análisis estadísticos más tradicionales, como los análisis factoriales y la proyección multidimensional a una propuesta de métodos cuali-cuanti, un campo en el que el autor siempre ha destacado. Propone la articulación topológica de distintas prácticas y técnicas de investigación social y que la topología puede ser el lenguaje de posible articulación entre las investigaciones sociales tradicionales y las que partan de los big data.
Los dos capítulos de la cuarta y última parte constituyen una reflexión sobre el nuevo mundo que nos aportan las concepciones dominantes sobre el big data, que nos llevan a sociedades de control. Los datos, por muy masivos que sean, no son la realidad; el manejo de cantidades ingentes de datos no elimina la subjetividad de los análisis, realizados casi siempre en función de unos intereses determinados. Por otra parte, los desarrollos relacionados con los big data se están llevando a cabo sin una necesaria base teórica.
El libro, editado por la UNED, está cuajado de múltiples ejemplos extraídos de investigaciones reales realizadas por el autor y sus colaboradores para diferentes empresas e instituciones.
Un libro imprescindible para quienes quieran aportar rigor a las investigaciones basadas en big data.